Not too long ago, I announced the publishing of my first journal article co-authored with Andrea Capiluppi and Cornelia Boldyreff. My mother was very proud — even if she did not understand a single word of it. I will give a brief summary of the article in this post, and if I succeed in whetting your appetite then you can go over to those nice people at Elsevier and buy the article.
The work examines a number of FLOSS repositories to establish whether there are substantive differences between them in terms of a handful of evolutionary attributes. My previous work on this issue has already been discussed in earlier posts. The earlier work compared a Debian sample of projects to a SourceForge sample. The attributes compared were:
- Size (in lines of code);
- Duration (time between first and last commit to the version control system);
- Number of developers (monthly average);
- Number of commits (monthly average).
It was found that Debian projects were older, larger, and attracted more developers who achieved a greater rate of commits to the codebase, all to a significant degree.
For the journal article we once again used this approach, but this time we cast our net wider and examined six FLOSS repositories, then set out to answer some questions. Is each repository significantly different to all others? Based on the results, what is the nature of these differences? And are there any notable similarities among repositories — after all, some of the repositories are very similar on the surface, as you will see. The chosen repositories were:
- Debian — a GNU/Linux distribution that hosts a large number of FLOSS projects;
- GNOME — a desktop environment and development platform for the GNU/Linux operating system;
- KDE — another desktop environment and development platform for the GNU/Linux operating system;
- RubyForge — a development management system for projects programmed in the Ruby programming language;
- Savannah — acts as a central point for the development of many free software projects particular associated with GNU;
- SourceForge — another development management system for FLOSS projects, and a very popular one at that.
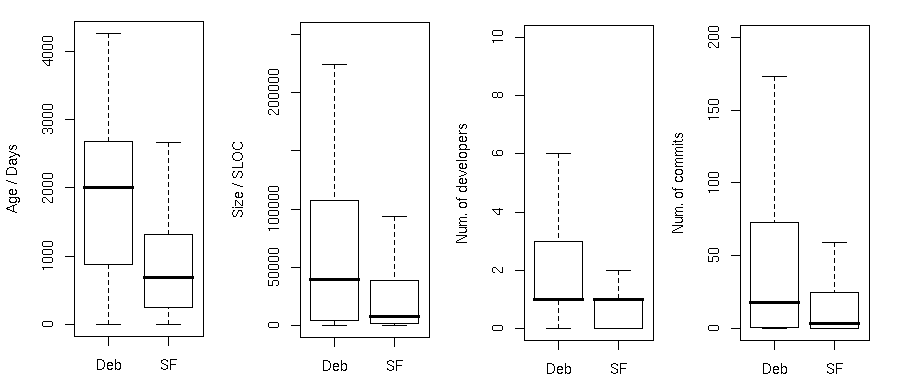
Once again we took a sample of projects from each repository and analysed each one to obtain the four metrics listed above. These values were aggregated together per repository. For an initial idea of the distribution of values we have these boxplots:

To answer the first question (is each repository different to all others) the answer is definitely no; some differences are clearly hinted at by the boxplots. To ascertain more about these differences, and answer the subsequent questions, we carried out paired comparisons for each repository (with 6 repositories that gives 15 combinations, hence 15 comparisons). For each comparison the difference was tested to see whether it was statistically significant or not. The exact figures are printed in the article, but this is the summary of what was found.
- Size: Debian was the clear winner. Projects in KDE and GNOME were of notably similar size, as were those in Savannah and SourceForge. The former group projects were smaller on average than those in the latter;
- Duration: These results furnished perhaps the most striking evidence of a measurable divide between the attributes of the chosen repositories (Debian, KDE, and GNOME on one hand, and RubyForge, Savannah and SourceForge on the other), which was observable in some other attributes . We were also suspicious of the RubyForge results given the extreme youth of the projects;
- Developers: Another divide between the two “groups” identified above;
- Commits: As with the average number of developers, Debian, GNOME and KDE all manage a higher rate of commits, but the significance of the differences from the other three repositories is weaker. We also suspect the RubyForge commit rate to be artificially high. As already noted, the projects in the RubyForge sample tended to have a very low duration. After a little deeper digging, we suggest that the projects in our sample may have been “dumped” into the repository (which records a number of commits) and quickly ceased any development activity, thereby inflating the monthly rate .
As mentioned above, detailed figures, procedures and conclusions are available in the printed article. And it does not end there… later in the article we went further. The patterns we found among the repositories were formulated into a framework for organizing FLOSS repositories according to evolutionary characteristics. This may have impact on individual projects existing in, and moving through, the ecosystem of repositories — definitely of interest to both researchers and developers alike, I hope.
 Excellent. The journal publication I co-authored with Andrea Capiluppi and Cornelia Boldyreff (“Identifying exogenous drivers and evolutionary stages in FLOSS projects”) has now been confirmed for publication in the May 2009 edition of Journal of Systems and Software. It is currently available online.
Excellent. The journal publication I co-authored with Andrea Capiluppi and Cornelia Boldyreff (“Identifying exogenous drivers and evolutionary stages in FLOSS projects”) has now been confirmed for publication in the May 2009 edition of Journal of Systems and Software. It is currently available online.