And so CSMR concludes. Still recovering from the conference dinner (surreally hosted in the Hotel Alcatraz, which used to be a prison — and that’s not a joke). Enjoyed it here, conversed with some really interesting chaps, and one or two personal heroes.
Let me wrap up with some bite-sized snippets:
Acceptance rate of papers: 31%
Best paper award: “Incremental Clone Detection” by Nils Gode and Rainer Koscher
Special award: Harry Sneed (“for leadership and many contributions to the practice and principled growth of software maintenance techniques and their industrialization.”)
Population of Kaiserslautern: 100,000 approx.
Time I have to wake up tomorrow to begin my journey home: 0545.
Today’s keynote was delivered by Tibor Gyimothy which looked at software metrics from the developer’s point of view. He presented the results of a study where developers were surveyed for their opinions on various metrics.
The developers were divided based upon such attributes as experience, platform knowledge (Java, C/C++, C#, SQL), and open source participation. They were questioned upon their opinions of metrics that measured size, complexity, coupling, and cloning, and the results were analyzed for correlations. The kinds of questions included “which metrics effect your understanding”, or “which metrics affect the testing effort”? There were many interesting differences between groups (too many to mention all), but examples included:
It was agreed that complexity, coupling, and clones affect understanding, but experienced developers disagreed with inexperienced developers whether size was an important factor.
Experienced developers were more insistent that smaller classes help testing.
Inexperienced developers tend to reject large generated classes, but experienced ones accept them.
Experienced developers prefer absolute metric values rather than the change in the values.
Aside from the keynote, architecture certainly seems to feature heavily this year at CSMR — maybe I have a faulty memory, but it seems to be more so than before. The panel discussion, apparently the first such discussion at CSMR, stimulated some slightly intense debate on the subject of collaborative tool use between academia and industry. It was a shame that we had to cut short, because I do love a good debate. I hope that I see such discussions in future conferences, but I would suggest that it be conducted with a little tighter discipline. Participants were allowed to make slide presentations of arguments and run over allotted time; I’d prefer a format where the chairman presents the arguments and takes a firmer hold of the participants (like the TV programme we have in the UK Question Time).
Looking forward to tomorrow: the software evolution track and the European projects track featuring some meaty FLOSS stuff as well as yet more evolution.
Excellent. The journal publication I co-authored with Andrea Capiluppi and Cornelia Boldyreff (“Identifying exogenous drivers and evolutionary stages in FLOSS projects”) has now been confirmed for publication in the May 2009 edition of Journal of Systems and Software. It is currently available online.
How embarrassing. The weather in Kaiserslautern is bad, I’m an Englishman…. and I don’t have an umbrella.
But at least the Fraunhofer IESE Centre is a wonderful environment. Which leads me to quickly express my admiration of the German approach to technical research and development. Briefly, there are four “actors” in their setup: the universities and industry, which scarcely need elaborating on, are two of them. The other two exist in-between these other players. The Max-Planck institutes are outlets of basic research funded mostly by the state. The Fraunhofer institutes are centres of applied science that are mostly funded by contract work. Look them up to learn more.
Onto the conference itself. Today, the keynote was delivered by Dieter Rombach. He argued that when software engineering is being taught, too scientific an approach is taken, and also that people are not sufficiently versed in software engineering principles.
Many maintenance tasks, he argues, are able to be anticipated, and yet they are not prepared for. For example, if you develop software that is dependent upon the CPU, why should you not develop it in a way that makes it as simple as possible to adapt to a new CPU? When developers in the 1960’s and 1970’s developed systems and saved a few bytes by storing the year as two digits, their systems broke when the year 2000 arrived: the shame is, not on them for anticipating it, but on us for not learning from their mistakes.
To prepare for maintenance, Rombach advocates these principles:
An adroit use of the fundamentals: e.g. divide and conquer, traceability
Use of software product lines
Empirically proven best practices
Also worth mentioning is Carola Lilienthal’s paper on analyzing large-scale architectures and suggestions for keeping their complexity under control. Her approach is to compare the intended architecture of the system (e.g. layered architecture) to the actual architecture derived from code analysis. By borrowing from cognitive psychology her paper proposes three aspects for architectural complexity to be applied: modularity, ordering (whether the relationships between elements form a directed, acyclic graph), and pattern conformity. A recommendation is made to begin with a reference architecture and progress to a layered architecture implementing the interfaces as the system grows.
This year’s European Conference on Software Maintenance and Reengineering is in Kaiserslautern, Germany. I’ll be there, but my fellow researchers in the Centre of Research on Open Source Software won’t because we’ve been accepted to so many different conferences we have to divide ourselves up because it’s the only way we can afford to attend them all. So for the benefit of my colleagues (and you, dear reader, if you so wish) I’ll try and find time to blog about the more notable presentations I see there.
Part of the use to which I’d like to put this blog is to disseminate information about research methods and tools. But before I start writing posts with involved details it’s probably prudent to present some sort of overview of the whole thing. Of course, there is no single method that is used by all computer scientists, although each method usually tries to approximate the scientific method as closely as possible. Hence, what I have to talk about is not the method utilized by all researchers, but it is a common one in the sub-field of free/open source and software evolution.
It was, I think, Daniel German who first suggested the role of a software evolutionist — a kind of palaeontologist, or private investigator, of software. Like a detective or an archaeologist, the software evolutionist arrives at the scene. Before her is a program listing, thousands of lines long. She doesn’t know how it got to be in the state she finds it, but clues may be available for her to piece its development together.
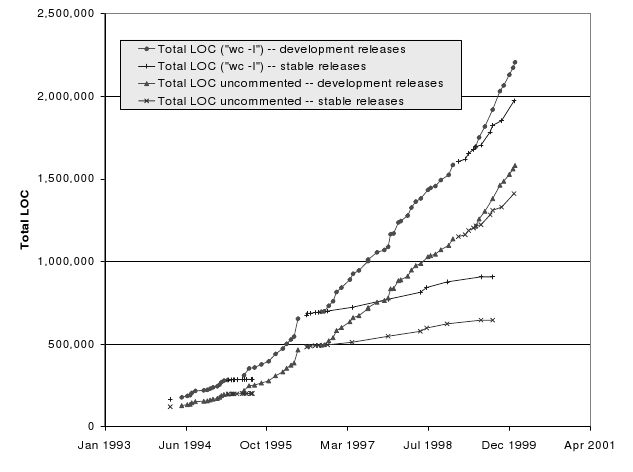
Linux kernel growth
Besides the code, there’s the support documentation (maybe that will tell her how the program is meant to function). Also open on the computer is a forum where all the developers communicate (perhaps this will shed some light on what the developers were assigned). And on the server is a version control system, a treasure trove of clues that shows exactly which developers did what, and when they did it.
Unlike the detective we’re not trying to find a murderer of course, but we are trying to piece together how the program developed over time, i.e. how it evolved. An early example of this was done by Michael Godfrey and Qiang Tu: with nothing but a load of historical releases of the Linux kernel between 1994 and 1999, they showed that the kernel grew at a super-linear rate (it grows by a larger amount as time goes by) and identified which parts of the kernel were responsible for this surprising growth. (Spoiler: the portion of the kernel that contains device drivers was the biggest driver of this growth.)
So how do software evolutionists do it? As I said I can’t speak for them all, but I’ll try to articulate an abstract version of the steps that I and others go through, and assume it approximates the experience of the rest.
Roughly speaking the typical steps involve:
Selection: Both of the project to study and the measures you wish to apply;
Retrieval: Getting hold of the software (not always easy!) and storing it appropriately;
Extraction: Parsing the raw data, extracting the pieces you are interested in, and constructing them into useful information;
Analysis: Applying the measures and performing your relevant test(s).
In later posts of this category I’ll discuss the tools and techniques of each stage, and (hopefully) build up a picture of the method. For now, I’ll show trivially how an analysis of the Linux kernel size might fit in with this approach (taking cues from Godfrey and Tu’s study where possible).
Selection: The Linux kernel is selected as a large exemplary open source project. Because the size is the attribute of interest, the number of lines of code is taken as a measure of size. To be scientific we should form some testable hypotheses predicting what we expect to find.
Retrieval: Each kernel version release is available on the Linux Kernel Archives as a tar file. Godfrey and Tu downloaded 96 of the releases.
Extraction: Now the lines of code (LOC) are counted in each release. Godfrey and Tu applied the Unix command “wc -l” to all *.c and *.h files and used an awk script to ignore non-executable lines.
Analysis: By this point, there should be 96 numbers stored, each the size of a release in LOC. To get a visual, we can feed them into a plotting program and produce a nice graph like the one above. We could even go further and apply all sorts of fancy mathematics or models. Suffice it to say, by the end of this stage we should have some results that allow us to confirm or refute our earlier hypothesis.
Once all this is done, we can then put forward out conclusions. Like a scientific study, the experimental data we have obtained is the evidence that backs them up.
The Computer Floss series continues over at YouTube. Here’s what was talked about in episode 2, “Myths and Misconceptions”:
A few myths and misconceptions have arisen over the years about what free and open source software actually is. This edition of Computer Floss addresses some of these and spells out what open source isn’t.
Myth: Open Source Software Costs Nothing
This is perhaps the most common misconception concerning open source, and it’s easy to see where this mistake comes from. Firstly, of course, our old bearded friend Richard Stallman, whom you should remember as the godfather of this open source thingamajig, when he came up with the idea, decided to call his creation “free software”. He meant “free as in freedom”, but in English free can also mean “free as in cost”.
Nowhere in the definition of free or open source does it state that software must be free of charge. In fact, the GPL, the General Public Licence, the most popular licence used to cover open source code, explicitly states that you may charge any price you wish when distributing.
The second reason is the fact that much open source software is available for no cost, which might lead people to believe that all of it is free of charge. As I’ll explain a little later, that’s not the case.
Myth: Open Source is the Same as Freeware/Shareware
Freeware and shareware are actually very different from open source. Both freeware and shareware are most definitely available without cost by definition, and, as we just learnt, this is not the case with open source software. But more importantly, freeware and shareware typically come with restrictions.
A freeware program can come with conditions such as allowing personal use only, or non-commercial use; furthermore, it may even come in a binary executable form only, and as we learnt in the first edition, that’s bad.
Shareware is only available on a trial basis, enforced by making it usable for a limited number of days or by taking out some functionality. Those restrictions will only be removed when you’ve coughed up the cash.
Myth: Open Source is Communism
This, frankly bizarre myth, equates open source software with Marxism. It’s hard to know exactly what someone means when they claim this: Communism advocates a stateless, classless society based on common ownership of property and means of production — not much to do with software.
It’s no better if we try and draw analogies: A central principle of Communism, “common ownership”, runs slap bang in opposition to the way that open source respects the author’s copyright. The author of a piece of open source code is still automatically the owner of that code, it’s just that the licence applied to the code grants certain rights to the users. Furthermore, another stated aim of communism is to end capitalism, so given that open source allows you to charge any fee you like for software, it’s really a lot more compatible with a market-based economy. In fact, open source might be a bit too pro-capitalist for some of those lefties.
Ballmer: shouty
It’s hard not to conclude that this labelling of open source software as communism is an attempt at FUD by those who prefer proprietary software, such as Steve Ballmer, the head of Microsoft, seen here in an old Microsoft advert.
Look at him, he’s insane — no seriously I think he might be quite ill.
Myth: Open Source Means You Can See the Source Code
Well, close; this brief definition doesn’t do the concept any justice, but get used sometimes, so it’s worth reiterating the basic tenets: Open source software requires that any user who requests access to the source code can obtain it (with or without a fee), and also grants that user the right to change and redistribute it. This is enforced by applying a licence to the that allows all users these rights; a licence that doesn’t allow them is *not* a free or open source licence.
Myth: There is No Accountability or Support in Open Source
People, especially businesses and other organizations, like to know that someone is responsible for their software when it goes wrong. A myth has grown, perhaps because much open source software is written by volunteers and enthusiasts, that no-one owns the software and therefore there is no accountability or support.
We’ve already established that open source code does have an owner, namely the author, but that author is under no obligation to support the software after its release. However, because of the nature of open source licences, what happens in practice is that organizations come along that take existing software, and offer support or warranty on it. Non-profit foundations like Mozilla or Apache, or companies like Red Hat or even IBM, are examples of organizations that are supporting open source software right now out in the real world. And this is in addition to the endless websites and forums where people can post problems, advice and fixes — a process made very much easier with access to the source code.
The tour through the comparison between Debian and SourceForge comes to a close by questioning whether Debian acts as a catalyst to evolutionary activity when a project is inserted into the repository. It has already been strongly suggested that projects packaged in Debian are recipients of significantly greater rates of activity.
Of the 50 projects in the Debian sample, 22 of them had a known history of evolutionary activity (monthly averages of number of developers and number of commits) that pre-dated its insertion into Debian, providing us with a “before” and “after”. So we compared the before and after of each project.
Developers
In 18 out of 22 projects, the distinct number of developers increases after being added to Debian. The remaining 4 experience no change, and have only 1 or 2 known contributors.
Commits
All projects have a greater number of commits in the after period than in the before period. However, the rate of commits in each period (the total commits within that period divided by its duration) only increases for 10 of the 22.
Summary
In summary of this trilogy I can say, from an absolute standpoint, that our results suggest Debian projects tend to be older, larger, attract more developers and a greater amount of activity, and all to a very significant degree. Furthermore, from an evolutionary perspective, the “Debian effect” seems to cause the pool of developers contributing to a project to increase when it is packaged by Debian, along with a half-decent chance that activity increases also.
And so, we revisit the posers put up in a previous post:
Are Debian’s evolutionary characteristics significantly different to those of SourceForge?
Does Debian act as a catalyst?
To answer these questions, we took a closer look at the software inside them. I’ll briefly explain the method here, but details of the steps will be part of later posts in the “Research Methods” strand.
We chose a mutually exclusive sample of 50 packages from Debian and 50 projects from SourceForge. In both cases they were taken from the pool of “stable” projects only. They were all downloaded and each project’s activity was extracted from their version control system (using log commands) and recorded in a file. Then we delved into our little toolbox and used some nifty tools to extract the information we needed, that information being the project’s:
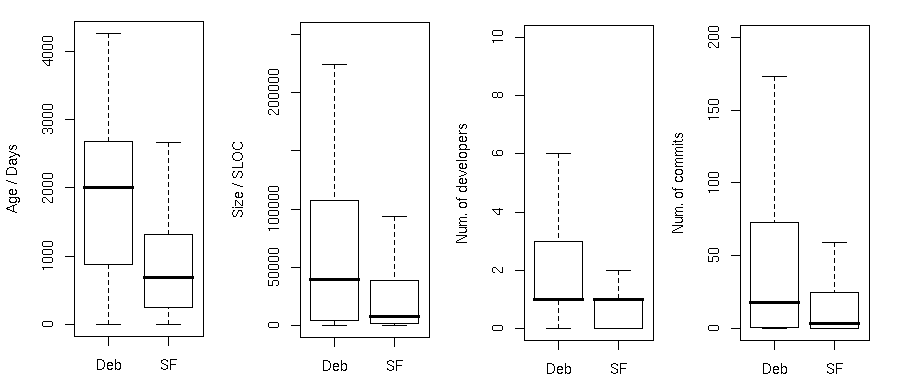
Age (time between first and last commit to the version control system)
Size (in lines of code)
Number of developers (monthly average)
Number of commits (monthly average)
Each attribute can be aggregated from the 50 projects into a summary value for the repository. So, for example, we can take the ages of the 50 Debian projects and use them to get a mean or a median age. If we do the same thing for SourceForge we can compare them.
And that’s just what we did.
And here’s just what we found:
Boxplots of measured attributes
Using statistical significance testing (again, I’ll cover this in a “Research Methods” post) we found that Debian projects had larger values for each attribute, i.e. they were older, larger, and attracted more developers who peformed a greater amount of work, all to a significant degree.
This leads us to our second question, is Debian responsible? Is it somehow a driver for these larger values? Our answer to this question comes in round 3.
We all know about SourceForge and Debian. Although they have different purposes, they both act as repositories of free software, and most of the practitioners will know that Debian hosts what is considered to be the best projects — judged most worthy by its army of package maintainers. Conversely, many (but by no means all) SourceForge projects languish in obscurity; these are, at best, of little interest outside of the developers who run them, or, at worst, have completely stalled. It is conventional wisdom then that Debian projects receive much more activity from developers than those on communities like SourceForge.
So today’s research question is: How true is this? How much more activity (if at all) do projects in Debian actually receive than their counterparts in SourceForge? To answer this query, two quantifiable and measurable questions are proposed:
Are the evolutionary characteristics of Debian projects significantly different from those in SourceForge? (In other words, do Debian projects receive so much more activity that we cannot conclude that random statistical noise is responsible for the difference?)
Does Debian act as a “catalyst”, so that when project are entered into Debian’s repository, the activity around the project increases?
To answer the questions, we need to measure proxies of evolutionary activity. We chose:
Project age
Project size
Number of developers
Number of commits
How these attributes were measured, and how they helped to answer the questions, will be addressed in the follow-up post.
 CSMR 2009 soldiers on.
CSMR 2009 soldiers on. Excellent. The journal publication I co-authored with Andrea Capiluppi and Cornelia Boldyreff (“Identifying exogenous drivers and evolutionary stages in FLOSS projects”) has now been confirmed for publication in the May 2009 edition of Journal of Systems and Software. It is currently available online.
Excellent. The journal publication I co-authored with Andrea Capiluppi and Cornelia Boldyreff (“Identifying exogenous drivers and evolutionary stages in FLOSS projects”) has now been confirmed for publication in the May 2009 edition of Journal of Systems and Software. It is currently available online.